This post will again not contain anything very advanced, but try to explain a relatively advanced concept by breaking it down into the ideas that led to its formulation. Once again, the star is that wonderful thing, linear algebra. I have gone from really disliking it upon first encounter (as a naive undergrad), to having immense appreciation for the way in which it can illustrate fundamental mathematical concepts. Here, I will first present some computations that could lead to the formulation of the spectral theorem in the finite dimensional case, and in the next installment I will consider instances of the generalisation. This is similar to how I would approach any new mathematical concept, which is first to reduce it to something I have a decent understanding of, before trying to understand it in any generality.
One version of the spectral theorem can be stated as follows:
Theorem. Suppose 
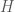
Recall that a compact operator is a linear operator such that the image of any bounded subset has compact closure. To get a good idea of the Spectral Theorem, we must first get an idea of what a compact self-adjoint operator would be in a finite dimensional setting. For the moment, let us only consider real matrices. Since the adjoint of a matrix is its conjugate transpose, in this case we consider only symmetric matrices. The question of compactness is trivial in this case. Our Hilbert space will just be 
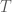

Since I don’t feel like working this out by hand, I’ll use some Python:
import numpy as np
A = np.array([[3,2,1],[2,2,3],[1,3,5]])
a = np.linalg.eig(A)
print(a) This gives us the following output:
(array([ 7.66203005, 2.67899221, -0.34102227]),
array([[-0.3902192 , -0.83831649, 0.38072882],
[-0.53490509, -0.13015656, -0.83482681],
[-0.74940344, 0.52941923, 0.39763018]])
Note that the eigenvectors are given as the columns of the array. Now, it would not be too much to expect that the eigenvectors will give us a basis for 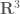
b = [np.dot(a[1][i],a[1][j]) for i in range(3) for j in range(3)]
print(b) (If you look at the code, you’ll see that I actually took the dot product of the rows, not the columns. Why would this have the same result?)
[0.9999999999999998, -5.551115123125783e-17, 2.7755575615628914e-16, -5.551115123125783e-17, 0.9999999999999998, -4.440892098500626e-16, 2.7755575615628914e-16, -4.440892098500626e-16, 1.0000000000000004]Those values are awfully close to either 0 or 1, and we can suspect that a precise calculation will probably give us those exact answers. But was this just luck, or would it work on any matrix? Let’s generate a random 4 by 4 matrix, which we multiply by its transpose to make it symmetric (where else do we see this product being used to generate Hermitian operators?):
B = np.random.rand(4,4)
BB = np.matmul(B, B.transpose())
bb = np.linalg.eig(BB)
c = [np.dot(bb[1][i],bb[1][j]) for i in range(3) for j in range(3)]
print(c)[1.0000000000000007, -8.881784197001252e-16, 5.689893001203927e-16, -8.881784197001252e-16, 1.000000000000001, 1.6653345369377348e-16, 5.689893001203927e-16, 1.6653345369377348e-16, 0.9999999999999989]Once again, we get entries that are practically 0 or 1, and it seems as if NumPy actually gives us the vectors in the desired form. You can get exact results using symbolic computation, for instance using SymPy:
import sympy as sym
A = sym.Matrix([[3,2,1],[2,2,3],[1,3,5]])
A.eigenvects()This takes surprisingly long however, and doesn’t tell us much we don’t know. We can now formulate a possible finite dimensional version of the spectral theorem:
Conjecture 1. The eigenvectors of a symmetric 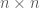
Let us first check this in the case where the matrix has full rank, and we have 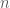



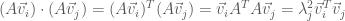
and

Since the dot product is commutative, we must have either that 




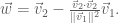
This new vector is also an eigenvector with eigenvalue 

Furthermore, 

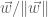
We can see that we must now replace Conjecture 1 with one that is more in line with the statement of the Spectral Theorem:
Conjecture 2. Given a real 
Now, where could this conjecture go wrong? In the above examples, we had nice, non-zero eigenvalues. So let us consider a matrix in which the columns are linearly dependent, and which has an eigenvalue of 0 with multiplicity 2:

A = np.array([[1,1,1],[1,1,1],[1,1,1]])
np.linalg.eig(A)
(array([-2.22044605e-16, 3.00000000e+00, 0.00000000e+00]),
array([[-0.81649658, 0.57735027, 0. ],
[ 0.40824829, 0.57735027, -0.70710678],
[ 0.40824829, 0.57735027, 0.70710678]]))As expected, we only have one non-zero eigenvalue, but we still have three orthonormal eigenvectors. NumPy has kindle normalised them for us, but it is easy to see that our eigenvectors will be multiples of 


All of this seems to support our conjecture (but is, of course, not yet a proof). Perhaps our conjecture can be made more general? Will it not perhaps hold for arbitrary matrices? Let’s pick an arbitrary integer matrix, generated for me by Python, and get its eigenvalues and eigenvectors:
[[ 1467. 418. -1015.]
[ 418. 1590. -1565.]
[-1015. -1565. -1560.]]
D = np.linalg.eig(C)
print(D)
(array([-2369.06809548, 1115.59533457, 2750.47276091]), array([[ 0.20557476, -0.80791041, 0.55228596],
[ 0.34091587, 0.58811029, 0.73341847],
[ 0.91734148, -0.03751073, -0.39633011]]))We check to see if we have an orthonormal basis:
E = [np.dot(D[1][i],D[1][j]) for i in range(3) for j in range(3)]
print(E)
[1.0000000000000002, 5.551115123125783e-17, 0.0, 5.551115123125783e-17, 0.9999999999999998, -2.220446049250313e-16, 0.0, -2.220446049250313e-16, 1.0000000000000002]
Within computational error, this is definitely what we want. One can have some more fun with this by generating a 
This has been fairly simple, but the goal is to study the spectral theorem in its full form. I an upcoming post, I will consider some more interesting operators on infinite dimensional spaces.
