Caveat: I am not a Python expert. I’m just messing around with it.
In a previous post, I used Numpy to calculate some eigenvectors of a four-by-four random matrix . Of course, these values were not exact, since we weren’t using symbolic computation. I have been experimenting with Cython recently in order to speed up some of my (very long) Python calculations, and I was wondering if I could use it to write code which gets close to Numpy speed and accuracy in the computation of eigenvalues. Numpy libraries are C-optimised already, so we shouldn’t be surprised if I can’t easily surpass them. However, this is a good exercise and introduction to using Cython for matrices.
Using Cython is slightly more complicated than simply slotting new commands into Python. You have to install Cython, create a .pyx file with your code, and create a setup.py file. This tutorial has everything you need to get started:
https://pythonprogramming.net/introduction-and-basics-cython-tutorial/
We will now implement an algorithm in Numpy to calculate the largest eigenvalue of a matrix, and compare it to standard Numpy functions. This is based on the power method, which works as follows: Given an initial vector 
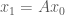




First, I am going to give the Python code, applied to a simple matrix for which it is easy to calculate the eigenvalues and eigenvectors by hand.
import numpy as np
import time
# This function takes iterates of the matrix multiplied by an initial vector
# It also gives the Rayleigh quotient at the end
# We give inputs the matrix x, the initial vector i, and the number of iterations
def largesteig(x,i,n):
for j in range(n):
y = np.matmul(x,i)
i = y
a = i
b = np.matmul(x,a)
bb = b.transpose()
bbb = np.matmul(bb,a)
#print(bbb)
c = np.matmul(a.transpose(),a)
d = bbb/c
return d
# We now choose the matrix to which we'll apply the function
B = np.array([[2,-1,0],[-1,2,-1],[0,-1,2]])
I = np.array([[1,1,1]])
K = I.transpose()
t1 = time.time()
def eiglist(A,J,n):
for i in range(n):
print(largesteig(A,J,i))
t2 = time.time()
print('The algorithm took {} seconds'.format(t2-t1))Note that we really weren’t careful in choosing the initial vector. The output of the iterations is as follows:
[[0.66666667]]
[[2.]]
[[3.33333333]]
[[3.41176471]]
[[3.41414141]]
[[3.41421144]]
[[3.4142135]]
[[3.41421356]]
[[3.41421356]]
[[3.41421356]]
[[3.41421356]]
[[3.41421356]]
[[3.41421356]]
[[3.41421356]]
[[3.41421356]]
The algorithm took 0.003749370574951172 secondsIt seems like this clearly converges, and quite quickly. (Of course, things can still go awry. I have had experiences where the output seems to stabilise, but with more iterations goes completely wrong.) We can compare the speed with Numpy’s usual way of solving for eigenvalues:
import numpy as np
import time
B = np.array([[2,-1,0],[-1,2,-1],[0,-1,2]])
I = np.array([[1,1,1]])
K = I.transpose()
t1 = time.time()
A = np.linalg.eigvals(B)
a = max(A)
t2 = time.time()
print(a)
print("Numpy took {} seconds.".format(t2-t1))This give us the output
3.4142135623730914
Numpy took 0.0005006790161132812 seconds.This is a lot faster, which should not surprise us greatly, since the Numpy code is optimised. We can increase the speed of our power method code by specifying fewer iterations (or preferably, by introducing some convergence criteria), but we still won’t get close to Numpy. Now let us see if we can close the gap by using some Cython. I am not under the illusion that we are going to beat Numpy to the largest eigenvalue, but even getting close should demonstrate the worth of using Cython in your Python code. All we are really going to do is say what types the different variables are. Usually, this is not necessary in Python, because it is “dynamically typed”. While this makes Python easy to read, it unfortunately slows it down quite a lot. The following script will not be the usual .py file, but .pyx instead.
import numpy as np
import time
cimport numpy as np
def largesteig(np.ndarray[np.int_t, ndim = 2] x, np.ndarray[np.int_t, ndim=2] i,int n):
for j in range(n):
y = np.matmul(x,i)
i = y
b = np.matmul(x,i)
bb = b.transpose()
bbb = np.matmul(bb,i)
#print(bbb)
c = np.matmul(i.transpose(),i)
d = bbb/c
return dAll we have done is specify the matrix properties (integer entries and dimension). Notice that we had to cimport numpy apart from importing numpy as usual. Before we can use it, we have to create the following .py script. Just call it setup.py:
from distutils.core import setup
from Cython.Build import cythonize
import numpy
setup(ext_modules = cythonize('Power_method_with_Cython.pyx'),include_dirs=[numpy.get_include()])In the terminal, we then run the command
home@home:pathtoyourfiles$ python setup.py build_ext --inplaceFinally, we have the following Python script to use what we have built on an example:
import Power_method_with_Cython as PmC
import numpy as np
import time
B = np.array([[2,-1,0],[-1,2,-1],[0,-1,2]])
I = np.array([[1,1,1]])
K = I.transpose()
t1 = time.time()
print(PmC.largesteig(B,K,10))
t2 = time.time()
print('The algorithm took {} seconds'.format(t2-t1))Once we have run the above, we get the output
[[3.41421356]]
The algorithm took 0.00029778480529785156 secondsThis is actually pretty unbelievable – we have only added a few type declarations in our functions, specifically to do with matrices, and we are already surpassing Numpy speed! The algorithm may still take longer than Numpy though, depending on the number of iterations used. Then there are further issues about convergence of the method, since a solution is not necessarily stable under more iterations. Still, pretty good for a small change in the code. There are even more ways to speed things up, some of which I might add to this post (once I understand them). Interestingly, I’ve discovered that some of the Cython commands which are supposed to speed things up could actually slow them down, but more one that later.
Some useful links:
https://stackoverflow.com/questions/28727717/how-are-numpy-eigenvalues-and-eigenvectors-computed
https://blog.paperspace.com/faster-numpy-array-processing-ndarray-cython/
