There are occasional, serendipitous events that make one suspect that there may be some benevolent animating power behind the universe. (This only lasts until the next annoying thing happens.) In August 2017, I was leaving San Francisco for Calgary after attending a workshop at AIM. On the flight, across the aisle from me, I saw someone editing what was clearly some mathematical papers. I introduced myself, and the other party turned out to be none other than Jacob Fox, on his way to a meeting in Banff. After parting ways, I started to look at some of his papers, and one immediately caught my eye, namely A relative Szemerédi theorem (with Conlon and Zhao). I had a problem that I’ve been working (and been stuck) on for a while, and this paper gave me a crucial theorem I needed to continue.
This paper also introduced me to the idea of hypergraph complexity, which I don’t yet understand, hence this post. We’ll start with some basic definitions and concepts.
Definition 1. Let 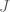
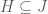


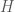
It should be clear that this just generalises the notion of an edge as a choice or two elements, to a choice of an arbitrary (but constant) number of elements. Hypergraphs give us some nice generalisations of Ramsey-type results, for example,
Theorem 1. [2] An infinite 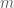
The nonstandard proof of this (which can be found in [2]) involves a beautiful use of iterated nonstandard extensions, a somewhat tricky (but very useful) subject I will probably address in a later post.
In what follows, we restrict our attention to finite hypergraphs. We firstly need to define a hypergraph system:
Definition 2. [1] A hypergraph system is a quadruple 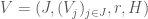
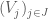

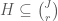
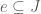
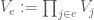
What would be a reasonable hypergraph system, and what would it be good for? Since the concept occurs in a paper concern a Szemerédi-type theorem, it seems reasonable that they have something to do with arithmetic progressions. To make this clear, we’ll need the notion of a weighted hypergraph, which we’ll illustrate by means of an example. Set 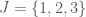
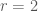

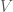
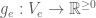

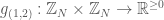
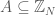


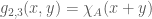

The product 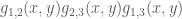

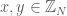


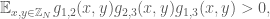
This is a simplistic example, and not nearly sufficient to characterise the existence of 3APs. For instance, we make no mention of the issue of wrap-around progressions in the cyclic group 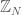
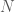
Suppose we are given a hypergraph system as above.
Definition 3. [1] For any set 
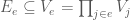
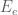
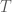
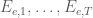


Thus, in the above example we would let 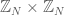
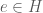
To make sense of the latter part of the Definition 3, let us first discuss what the required cliques are (following [1]). If 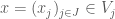
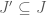



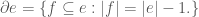
In a 2-uniform hypergraph as above, for 
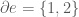
If we now say that 
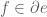

for all 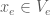
To be fair, this does not make anything very clear, so let’s unpack this notion further with our very simple example of a (complete) 2-uniform hypergraph, by trying to understand what a satisfying notion of complexity should be. Taking the edge 
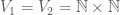
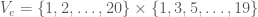

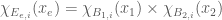
for all 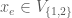
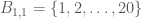


Let’s see if the same reasoning applies to 3-uniform hypergraphs. Let 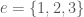
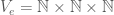



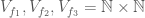

A little consideration will show that the same trick employed above works here as well, because our set 
Consider now the following subset of the above set
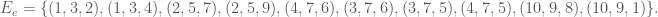
This set can’t be written as a single Cartesian product of subsets of the sets we are considering, and seems slightly more random in character, so there is a hope that the complexity should be higher. Setting 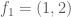
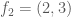

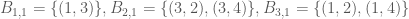

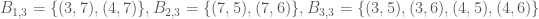

(where the notation has been shortened in an obvious way). To avoid confusion, we note that there are elements 
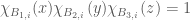
Of course, the case of a 3-uniform hypergraph is quite easy to analyse this way, because two of the edges determine the third, and the difficulty of generating such examples will increase rapidly for higher
Intuitively, the example at least makes clear that the complexity of the hypergraph is somehow determined by how easily the set
Shameless self-promotion: If you enjoy Fourier series and Martin-Löf randomness (or Kolmogorov-Chaitin-Solomonoff randomness – take your pick), see my paper in APAL. For something similar, involving Carleson’s theorem and Schnorr randomness, see the paper by Franklin, McNicholl and Rute at https://arxiv.org/abs/1603.01778.
References:
- A relative Szemerédi theorem, David Conlon, Jacob Fox and Yufei Zhao
- Nonstandard Methods in Ramsey Theory and Combinatorial Number Theory, M Di Nasso, I Goldbring and M Lupini
